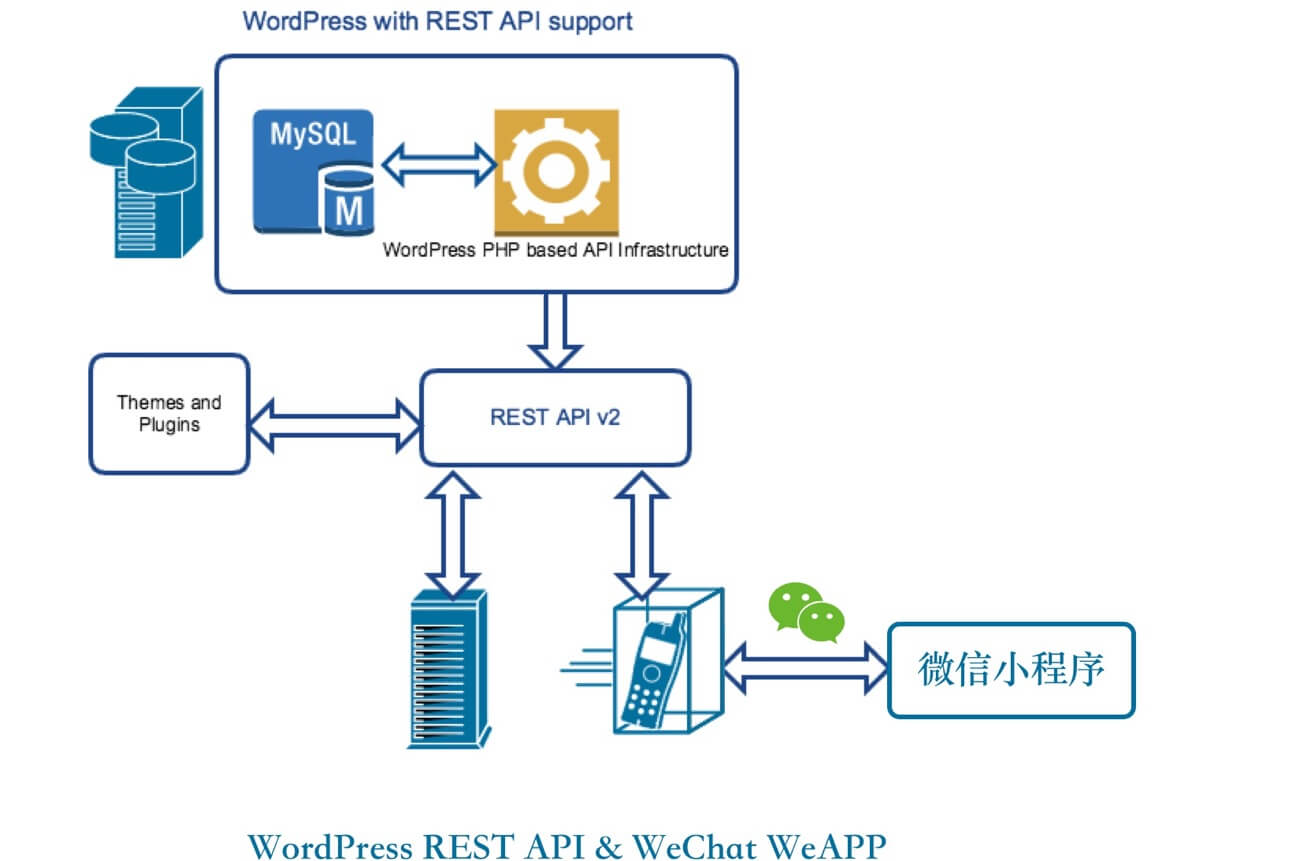
WordPress REST API功能开发趋于完善,通过REST API可以轻易获取wordpress网站的文章数据、页面数据、用户数据等。基于wordpress开发微信小程序其实就是通过wordpress的REST API获取这些数据,然后以一定的方式在小程序端进行数据处理后使用前端代码渲染,因此基于WordPress开发微信小程序,对于不擅长写后端代码的开发者就省去了不少的烦恼。
接下来就以DeveWork开发的“DeveWork极客小程序”第一版v1.0 为例,介绍三个页面(首页、内容页、阅读记录页)大体上是如何做出来的。可以扫描下面的小程序码体验一下DeveWork极客小程序(已经不是v1.0版)

注意:要看懂本章节的内容,需要把一遍微信小程序官方开发文档,先对小程序开发有一定的了解,另外本章节也不会涉及如何写CSS(WXSS)的部分。
准备工作
- 在微信公众平台管理后台上注册小程序账号,并配置域名等信息
- 配置好服务端HTTPS、
- 准备已经备案的域名(即“合法域名”)
提示:本例作者开发之前对WordPress REST API 进行了一些定制化的输出(如:禁止文章某些字段显示、输出post meta所有字段、输出post meta特定字段等)
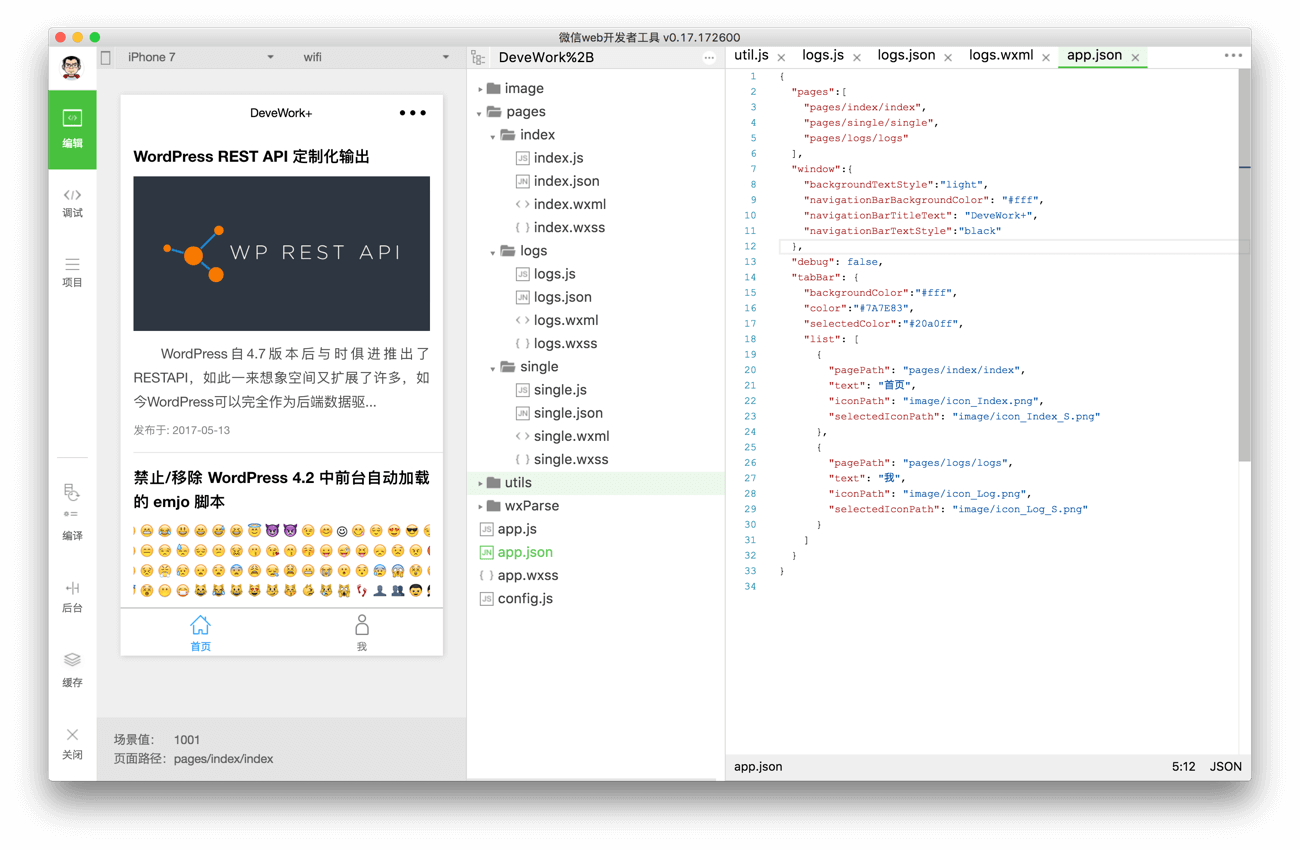
项目结构
结合微信官方quick start 的例子与个人需求,将项目结构如下分好:
.
├── app.js
├── app.json
├── app.wxss
├── config.js // 配置文件
├── image // 图片目录
├── pages // 页面目录
├── utils // 实用untils 类
└── wxParse // 第三方库wxParse
小程序首页(文章列表页面)
首页即文章列表页面, 即展示最新的5篇文章,然后通过下拉流式加载更多文章(有点无限加载的意味)。使用到WordPress 的REST API 就是your-site.com/wp-json/wp/v2/posts?per_page={num}&page={num}。
index.js文件里面核心是通过wx.request接口访问上面的API URL获取到文章数据并setData 供后续数据渲染:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | wx.request({ url: url, success: function (response) { self.setData({ posts: self.data.posts.concat(response.data.map(function (item) { ... // 数据过滤/格式化等 ... return item; })) }); } }); } |
上面的代码我是抽出在一个函数中,方便后续重复调用。设置的数据通过index.wxml 循环输出,当前在此之前因为要做滚动加载,所以采用了小程序的scroll-view组件(官方文档)。
1 2 3 4 5 6 7 | <scroll-view scroll-y="true" bindscrolltolower="pullDownRefresh"> <block wx:for-items="{{posts}}" wx:key="{{item.id}}"> <view class="entry" index="{{index}}" id="{{item.id}}" catchtap="redictSingle"> <!--文章数据的展示,细节代码略过--> </view> </block> </scroll-view> |
上面的WXML 代码中绑定了两个事件函数:一是下拉事件pullDownRefresh(),一个是点击事件redictSingle(),即点击后跳转到文章详情页。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | // 下拉刷新 pullDownRefresh: function (event) { var self = this; self.setData({ page: self.data.page + 1 //页面+1 }); console.log('current page:' + self.data.page); this.fetchData({ page: self.data.page }); }, // 路由导航到文章内页 redictSingle: function (event) { console.log('redictSingle'); var id = event.currentTarget.id; // 这里的id 其实是WordPress 中的文章id,需要传递到single 页面 var url = '../single/single?id=' + id; wx.navigateTo({ url: url }) } |
文章内页(文章详情页面)
文章页使用到的REST API URL是your-site.com/wp-json/wp/v2/posts/{id}。也是类似,通过wx.request接口访问URL 然后渲染数据到WXML 页面上。代码与上面的类似就不重复了。
这里其实涉及到个如何将富文本转为微信小程序可识别的WXML的问题。因为获取的JSON 数据文章正文部分是一段HTML 代码,如果直接输出是会报错的,需要将这段HTML代码(俗称富文本)转化为微信小程序WXML语言。Jeff使用的是WxParse这个第三方库,不过这个库目前来说依然不是很完善,接上去之后发现有不少bug,还好凭借自己的技术给打补丁般一个个修复了。
使用上,按照WxParse的文档,在获取到文章数据后,经过html to wxml的步骤后赋值到page data:
1 2 3 4 5 6 7 | // html to wxml let article = res.data.content.rendered; WxParse.wxParse('article', 'html', article, self, 5); self.setData({ wxParseData: article.nodes }); |
wxml上,import导入wxParse.wxml并调用:
1 2 3 4 5 | // html to wxml <import src="../../wxParse/wxParse.wxml"/> <view class="entry__cotent "> <template is="wxParse" data="{{wxParseData:article.nodes}}"/> </view> |
以上就是接入WxParse 的过程粗略介绍。
提示:小程序现在出了富文本组件(rech-text),个人评价么,暂时还比不上 wxParse。当前支持的标签有限(如pre标签不支持)且不支持绑定事件,暂时还是先用着wxParse。
阅读记录页面
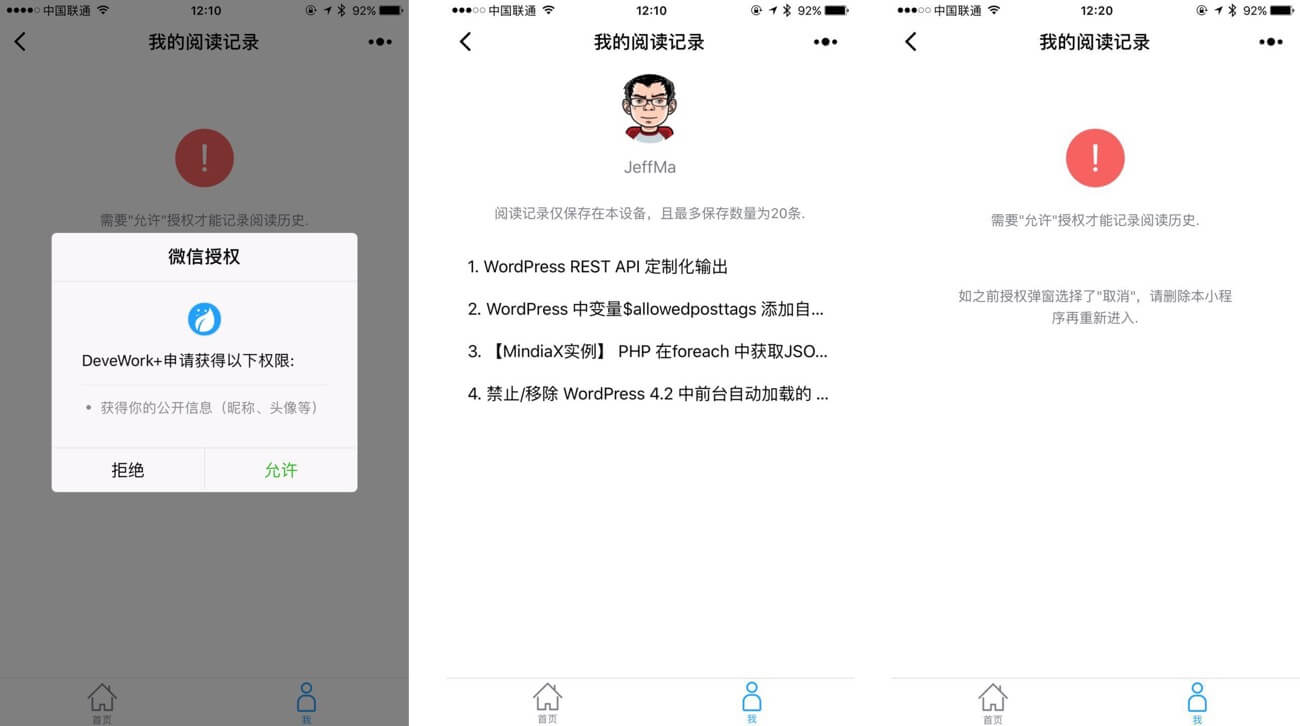
阅读记录页面是用来展示用户浏览历史,直接照着官方的Hello World例子就做起来了。这个页面用到的主要如下两种接口:LocalStorage 相关接口、用户授权相关接口(wx.login,wx.getUserInfo等)。
从用户体验上考虑,不应该一开始就向用户申请授权,而是有需要的页面才申请;同时也应该做好用户不允许授权的优雅处理。在这里因为小程序的坑以及个人关系第一版处理得不是很完美,代码就不展示了。
提示:处理授权相关的内容参考本文《提升用户体验,微信小程序“授权失败”场景的优雅处理》
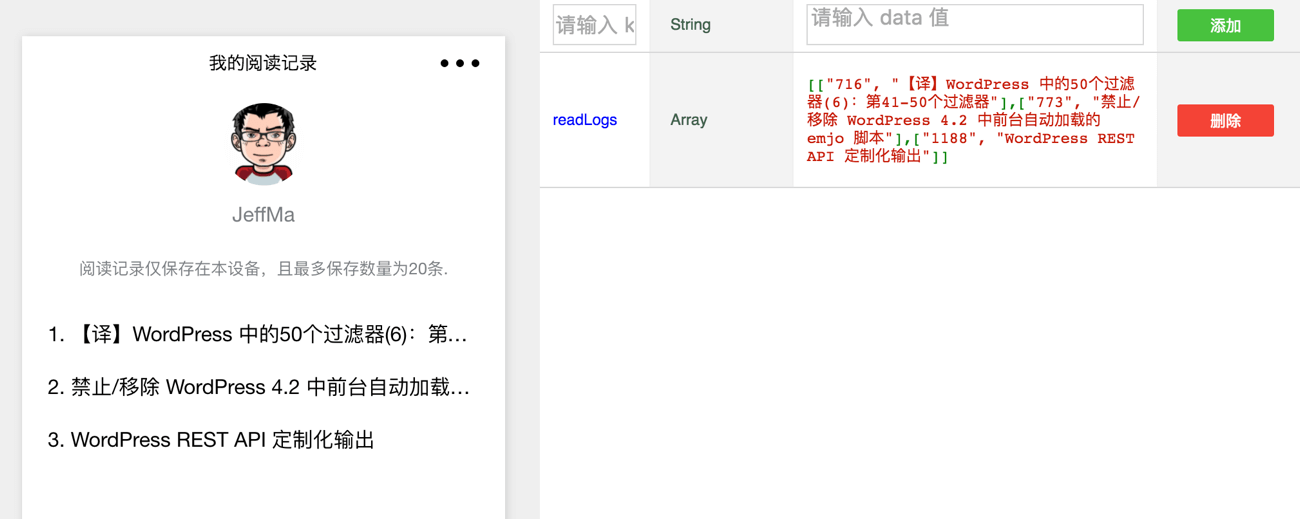
记录的文章阅读历史数据是以LocalStorage的形式保存在客户端而非云端,一句“阅读记录仅保存在本设备”的提示是有必要的。同时基于容量上的考虑将最多数目限制为20条。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | // 调用API从本地缓存中获取阅读记录并记录 var logs = wx.getStorageSync('readLogs') || []; // 过滤重复值 if (logs.length > 0) { logs = logs.filter(function (log) { return log[0] !== id; }); } // 如果超过指定数量 if (logs.length > 19) { logs.pop();//去除最后一个 } logs.unshift([id, response.data.title.rendered]); wx.setStorageSync('readLogs', logs); |
上面的代码其实是放在single.js里面的,因为需要将文章id与标题保存在LocalStorage 上,只有single.js才同时获取这两种数据。
最后还需要在log.js的onShow生命周期绑定一个更新数据的函数:
1 2 3 4 5 6 7 8 9 | updateData: function(cb){ var that = this; // readlog this.setData({ readLogs: (wx.getStorageSync('readLogs') || []).map(function (log) { return log; }) }) }, |
经验篇
主要记录在开发过程中的一些坑以及解决方案。
TabBar 的图片问题
小程序官方宣称支持SVG 图片,但在tabBar 里面的图片并不支持SVG 图片。官方推荐采用81×81 尺寸的png 图片,但这个依然有点坑。建议在设计icon 的时候稍微留点透明的padding 占位,不然会导致图标在真机上会放得很大。
图片防盗链的referer 设置
如果你托管图片的服务器有防盗链处理,那么得将servicewechat.com放入白名单中,并不是想当然的qq.com。
Image 的绝对路径必须以https 开头
image 的src 绝对路径,在web 开发中是允许类似//example.com/pic.png的以//开头的存在,这种图片路径在微信web 开发者工具也能正常显示,但在真机上就不能正常加载了,必须是https 开头的绝对路径。
服务端数据侧不好处理的话可以通过下面的util 处理:
1 2 3 4 5 6 7 | // 补全URL 中缺失的 HTTPS function addhttps(url) { if (!/^(f|ht)tps?:\/\//i.test(url)) { url = "https:" + url; } return url; } |
开发者工具的小程序UA 与实际UA 不同
开发工具中模拟的小程序UA 是类似:
… Chrome/53.0.2785.143 Safari/537.36 appservice webview/100000
而通过Nginx 的log 可以查看到实际的UA 是类似(其实就是微信的UA):
… Mobile/14E304 MicroMessenger/6.6.0 NetType/WIFI Language/zh_CN
某些情况下需要注意这些不同。
默认的Flex 布局
如果你是在官方例子的代码基础上开发你的小程序的,建议先删掉app.wxss的flex布局相关代码,会降低你遇到奇葩样式问题的概率。
wxParse 的坑1:code 字符被错误替换
小程序使用到的富文本转化是用wxParse 这个第三方库,用的时候发现有不少坑(但目前是这个库最为实用了)。其中一个就是全局的code 字符都被替换为wx-codexxx 类似的坑,作者本意应该是对code 标签进行这个替换,但可能一不小心写错了。解决方案是暂时删掉那段代码。
wxParse 的坑2:image的src多解析出一个逗号
看图说话:
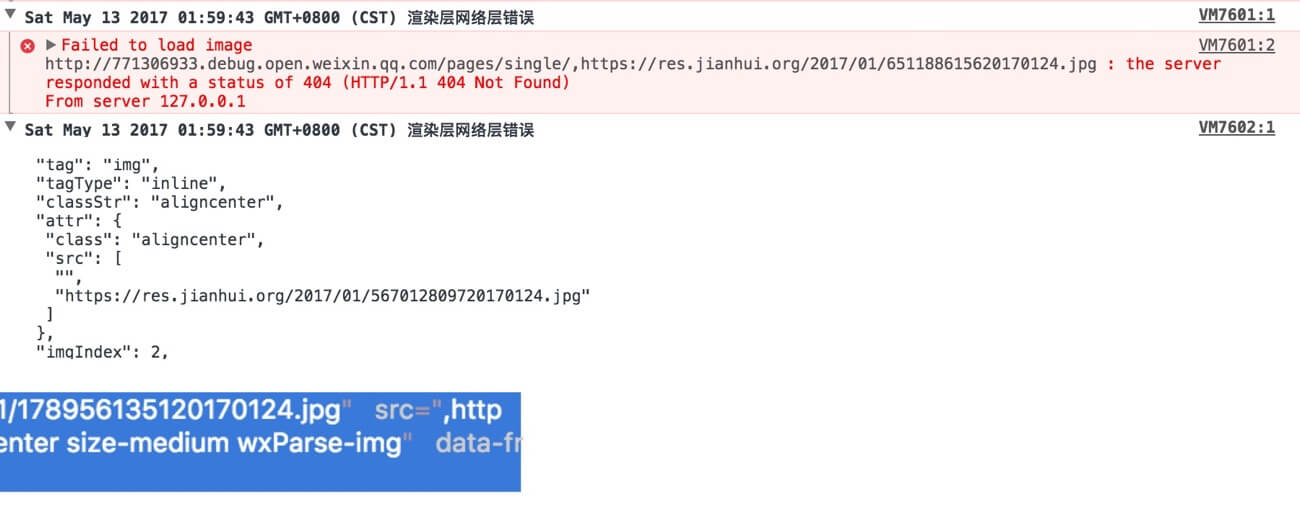
上图也很好解释了上面的referer 坑与图片路径https 开头的坑。解决方案只能先改动源码(html2json.js 约L130)Fix 下:
1 2 3 4 | // Fix: img 标签数组含有空字符的问题 if (imgUrl[0] == ''){ imgUrl.splice(0, 1); } |
总结篇
至此详略得当地介绍了开发这个WordPress 版小程序的过程,接下来的工作自然是提交到官方并耐心等待审核结果的通知。整个开发过程其实并不太有难度,如果之前有使用过Angular、Vue 这类MVVM 框架,整个开发过程基本上只是看官方文档的问题。
原文链接:https://devework.com/wordpress-rest-api-weixin-weapp.html